Part 4: Custom Metadata Type Relationships: Yes, It’s a Thing


Before we dive into Custom Metadata Type (CMDT) relationships let’s take a step back and review metadata and understand how it fits on the platform.
What makes Salesforce so flexible and easy to mold? It’s how the platform separates data from metadata data: each is stored in different tables. When we update, edit or delete a record, one set of tables are modified (data tables). When we change the definition of a field or update a workflow, a completely different set of tables are modified (these are considered metadata tables).
And of course we almost always update metadata through change set deployments, right? (because making metadata changes directly in production is a Really, Really Bad Idea)
Note that we are intentionally talking about ‘back-end’ tables and not Salesforce objects. These tables are hidden behind layers of abstraction that eventually provide us with the familiar Salesforce platform–including all those awesome objects (who doesn’t love Case and Lead objects? I mean really!). Check out this technical white paper that explores the nitty gritty of how the platform works in the back-end. Consider this a warning: it’s dense and technical (and wonderful for those nerdy/technical types).
http://www.developerforce.com/media/ForcedotcomBookLibrary/Force.com_Multitenancy_WP_101508.pdf
While it’s very obvious what data is, what exactly is metadata? Let’s make sure we are on the same page.
The data about data
At the purest level metadata is ‘data about data’. In the context of the platform it is almost everything that isn’t record data. It’s the stuff we update/change that impacts how data behaves and how the data is organized. Some folks like to say that custom objects and field definitions determine ‘the shape of the data’ (which sounds so nerdy cool). Generally, Salesforce metadata is the stuff that we put into changesets. Consider this: we regularly create metadata whenever we create a custom object. To get a bit more technical, when we define a new custom object we are actually creating a new Entity Definition metadata type entry (Entity Definitions is how custom objects are defined–tuck this nugget in the back of your mind for later).
Another metadata type we can create and manage are Custom Metadata Types (CMDTs). These behave a bit like custom objects–complete with fields and validation rules and can have rows. The difference is that these are all metadata–they are treated very differently than data.
Why we use CMDTs
Before we get into the CMDT relationship details let’s address the question: why would we want to use CMDTs in the first place? What’s the value? What’s the point?
CMDTs address the problem of storing and accessing specific configuration/setting information. A best practice has always been to avoid hard-coding volatile values in automations. Volatile simply means the value can change, usually based on evolving business conditions or technical needs.
A few examples of volatile values can be:
- when a manager should be notified if an opportunity has been open too long
- number of days before a reminder email should be sent
- date criteria identifying records for a ‘clean-up’ batch job.
Having these values stored as configurable values provides flexibility avoiding the need to update the automation which in turn minimizes risk and improves implementation time.
Way back in time, the original method for configuration/settings was to create a dedicated custom object. While that worked it did create more overhead in terms of resources and governor limit consumption. Salesforce came to the rescue with Custom Settings–a different metadata type–that allowed us to create a place to store configuration data that had little impact on governor limits. The challenge with both of these solutions is that when deploying either between instances (sandbox to prod) any configuration information would need to be re-populated in the target org. What a pain.
Salesforce thus introduced the CMDT–where each ‘row’ of the CMDT is metadata and can be deployed together with the other components in a changeset; thus keeping the configuration details intact. Pretty cool.
And it’s powerful: CMDTs can be referenced in code, flows, processes, formulas and validation rules (unfortunately not in workflows–there is an Idea to enable it–not optimistic regarding this one).
Wait. There’s more!
With CMDT, Salesforce added the capability to support relationships between a few different metadata types. It’s really, really cool and that’s the reason we are here and why these matter.
To sum up, CMDTs allow us to store config data that is available to most automations. There’s obvious tremendous value in that. What is less obvious is the value behind CMDT relationships. Let’s explore how they work and the value they can provide.
Metadata Relationship Types
There are four ‘flavors’ of the Metadata Relationship–though when we create the relationship in Setup it appears as a single option:
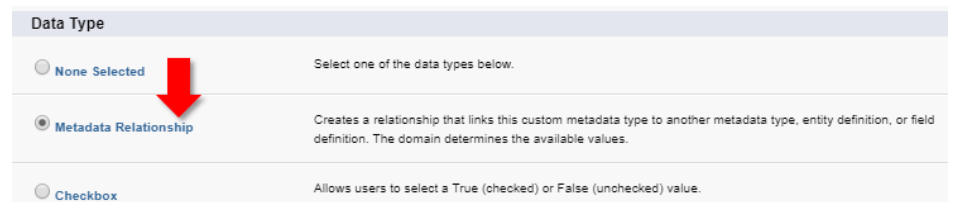
On the following page we can select with what specific metadata relationship we want to leverage (the options displayed will be any other existing CMDTs and Entity Definition). Note that the other Metadata Relationships (Field Definition and Entity Particle)–which we will discuss shortly–has a dependency on Entity Definition and will not be available on that particular CMDT until there is an existing Entity Definition on the current CMDT.
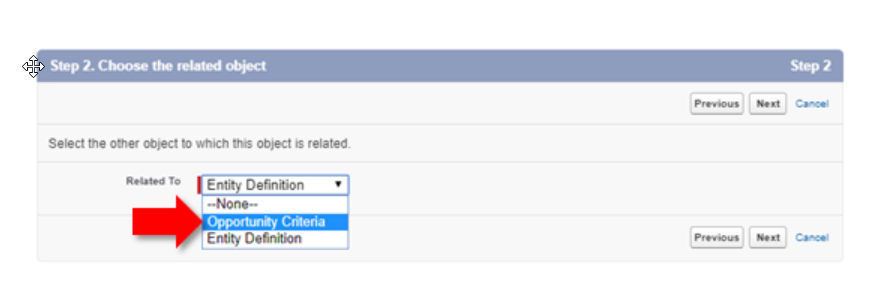
#1 Metadata Relationship-Custom Metadata Types
This allows us to relate one CMDT ‘object’ to another creating a parent-child relationship. Yep–we can create hierarchies with CMDT objects.
Consider a complex business requirement that needs to evaluate Opportunities–based on different sets of criteria–which, in turn is used by code to generate a number of Cases (based on the Opportunity’s criteria). Using CMDTs we can define a parent CMDT that contains the Opportunity criteria to be matched against–and as a child another CMDT that would contain metadata records–one for each Case type that is to be created for the matched Opportunity. The CMDT data model can look like this:
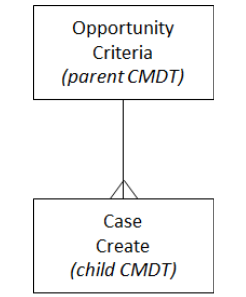
Consider a complex business requirement that needs to evaluate Opportunities–based on different sets of criteria–which, in turn is used by code to generate a number of Cases (based on the Opportunity’s criteria). Using CMDTs we can define a parent CMDT that contains the Opportunity criteria to be matched against–and as a child another CMDT that would contain metadata records–one for each Case type that is to be created for the matched Opportunity. The CMDT data model can look like this:
Where the flexibility comes in: the Opportunity Criteria CMDT can contain editable fields that store the values that need to be matched; the Case Create CMDT can have rows updated, added or removed to control what Cases and how many are generated. We haven’t stated this explicitly: in order to leverage the CMDTs as described in this use case we would need to use flows or code.
#2 Metadata Relationship-Entity Definition
We can also associate a CMDT to an Entity Definition metadata entry (remember we mentioned previously that Salesforce objects are each defined by their Entity Definition). Building upon the example from above, let’s say the Opportunity Criteria has an Entity Definition relationship field named ‘Opportunity’ (in this example we named the field ‘Opportunity’–it could have any name).
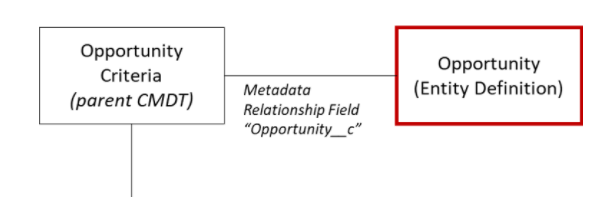
What does creating an Entity Definition relationship field on a CMDT give us? When we finally create an Opportunity Criteria CMDT record that Entity Definition field (we named Opportunity, remember?) is rendered as a picklist that displays a list of almost all of the org’s objects we would normally care about–allowing us to select the object that we want to associate to the CMDT record. Despite the fact that the field is named Opportunity, any object could be selected. For our example, we want to make sure that only Opportunity is selected, and that’s where CMDTs support for validation rules help.
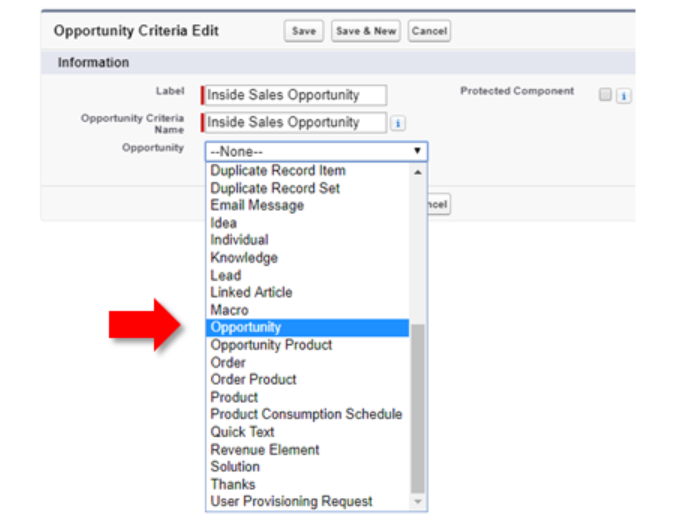
By itself this is interesting. When paired with the last two ‘flavors’ of Metadata Relationships and a little extra effort it can be darn useful. Let’s take a look.
#3 & #4 Metadata Relationship-Field Definition or Entity Particle
This relationship allows us to relate specific fields to the CMDT and is only available once an Entity Definition relationship has been defined (as noted earlier).
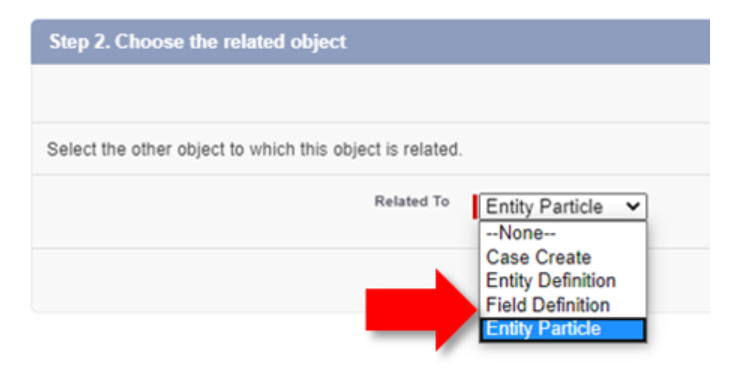
Either the Field Definition and Entity Particle relationship require having the Entity Definition relationship field populated as their Controlling Field; which determines what fields could be selected in either the Field Definition or Entity Particle picklist on the CMDT record.
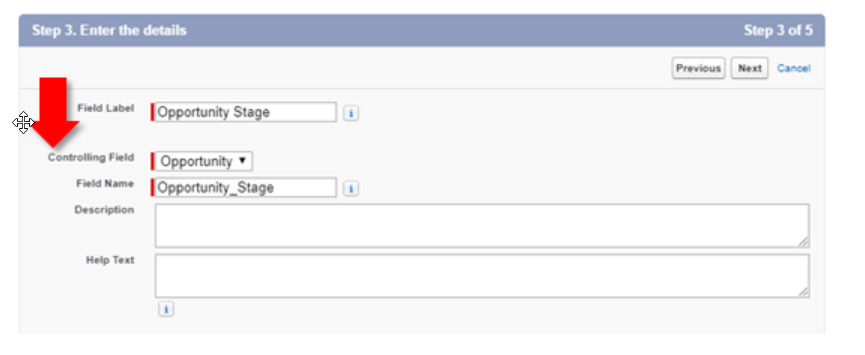
Once the Field Definition or Entity Particle field is defined, we can populate CMDT records with the name of the specific field from a dynamically generated picklist based on the object selected (in other words, pick the object and then pick the field from the selected object).
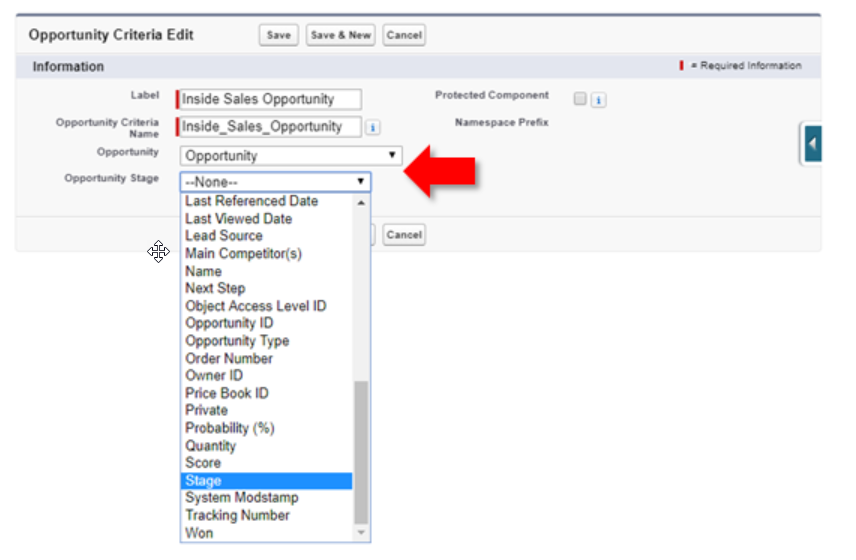
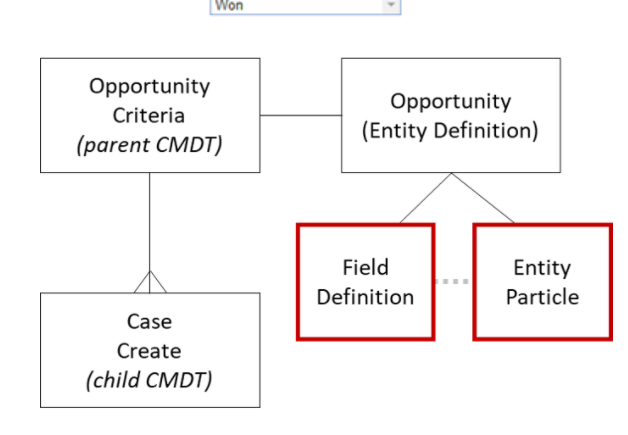
In this example we have updated the Opportunity Criteria CMDT. On it we’ve added two custom Metadata Relationship fields: Opportunity (Entity Definition relationship) and Opportunity Stage (Field Definition relationship). If we recall, the use case is that Opportunity Criteria would be evaluated to determine what Cases should be created (based on the child CMDT called Case Create that has a Custom Metadata relationship to the parent Opportunity Criteria). Using the Entity and Field Definition relationships guarantees that the correct object and field have been selected.
Think about the potential: this approach allows us to have multiple Opportunity Criteria records where each can use DIFFERENT Opportunity fields.
While we leveraged three CMDT relationship types we haven’t addressed the last part of the use case: the criteria to match against. That can be addressed by adding a text field to Opportunity Criteria called Stage Criteria Value. When we then create an Opportunity Criteria record it can be populated as below:
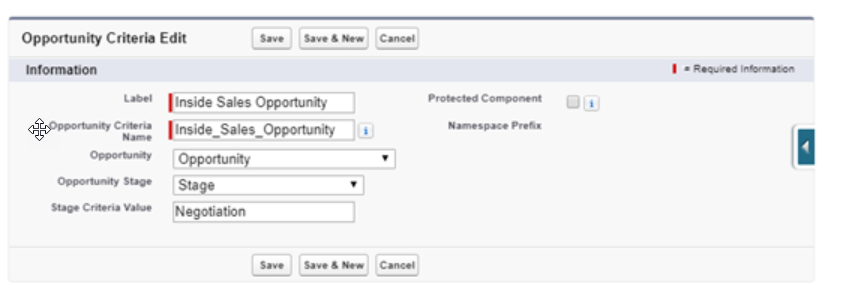
Now our flow or code can examine all the Opportunity Criteria CMDT records to find a match and once found can then find all the related child Case Create CMDT records creating a Case for each. If the business decides to add or change the stages on Opportunity then the CMDT can be updated and the automation–as long as properly built–will continue to work.
To reiterate the power of CMDT and Metadata Relationships: There is nothing preventing us from adding other sets of relationship fields on the Opportunity Criteria and adjusting the logic as necessary to have more granular control over the matching criteria.
Particle Man. Particle Man. Doing things an Entity Particle can.
(With apologies to They Might be Giants)
Wait–we discussed a use case using Field Definitions without digging into Entity Particles. Let’s address that now. Entity Particle relationships are relatively new for CMDTs (while new on CMDT they are NOT a new metadata type–they’ve been around for a while). At first blush they look like Field Definitions: Entity Particles represent the most basic element of a field, that can be considered a field. For regular fields like Account Name, there is no difference if we reference that field through Field Definition or Entity Particle. If instead we chose to take a look at Account’s Billing Address field we would see a big difference: Field Definition would display only the Billing Address field, Entity Particle would display Billing Address AND all the fields that make up the Billing Address (i.e. Billing Street, Billing Country, Billing Zip/Postal Code, etc.). What that means is that Entity Particles gives visibility to the base fields that make up compound fields (like Billing Address, Shipping Address).
So, which should we use? It really depends on the use case. Generally speaking, Field Definition is usually the better option (CMDT validation rules has built-in options for Field Definitions).If the automation (and we are talking code here) needs to pull from the CMDT the specific fields from a compound field then Entity Particle may make sense in that use case.
Metadata Relationship field characteristics:
- Can only be related to existing metadata types: Custom Metadata Type objects, Entity Definitions and Field Definitions
- Field Definition relationships are not available until an Entity Definition for the same CMDT is defined
- Entity Definition and Field Definition relationships are populated via picklists
- Cannot be self-referencing
- Custom Metadata Type relationships can be across multiple levels
There are some considerations regarding Custom Metadata Relationships found here: https://help.salesforce.com/articleView?id=custommetadatatypes_relationships_limits.htm&la_2=&type=0
In the next–and final–post in this series, “Relating to Data Off-Platform”, we are going to explore relating data from other systems with Salesforce objects. View the entire 5-part Salesforce Data Relationships series here.

- The Journey “We” Take to Better Salesforce Experiences - May 13, 2021
- What to Consider when Securing Salesforce with Multi-Factor Authentication - February 4, 2021
- Part 4: Custom Metadata Type Relationships: Yes, It’s a Thing - June 23, 2020



{kind=link}